Talend - HDFS with high availability
Github Project : example-talend-high-availability
Preamble (with all versions of Data Fabric)
This article is for using Talend on an HDFS with high availability option. The particularity of high availability is to have two namenodes for one HDFS, in case of failure.
The aim of this job is to work both in classical HDFS and high availability HDFS.
Configuration : Context
Create a group of context with 2 contexts. You can create with only one context and change variable value in commande line with --context_param option.
In this example DEV have no high availability and PROD have high availability.

The URI for the namenode in DEV is made with the namenode DNS and the port. In PROD the name of HDFS is cluster.
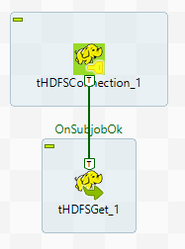
Get file from HDFS
- Create a new job
- Add the component "tHDFSConnection" : Allows the creation of a HDFS connection.
- Add the component "tHDFSGet": Get files from HDFS to local directory
- Create links "tHDFSConnection" is connected with "tHDFSGet" (through "OnSubjobOk")
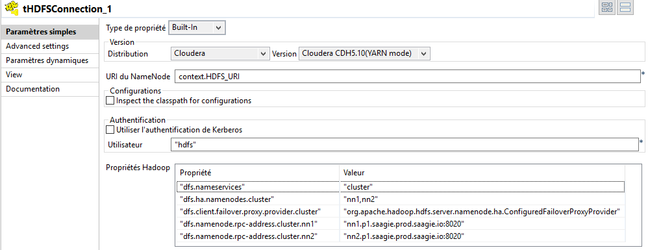
- Double click on "tHDFSConnection" and set its properties:
- Add a "Cloudera" distribution and select the latest version of Cloudera
- Enter the URI name node, here context.HDFS_URI
- Add the user
Add 5 properties :
Properties Value dfs.nameservices cluster dfs.ha.namenodes.cluster nn1,nn2 dfs.client.failover.proxy.provider.cluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.namenode.rpc-address.cluster.nn1 nn1.p1.saagie.prod.saagie.io:8020 dfs.namenode.rpc-address.cluster.nn2 nn2.p1.saagie.prod.saagie.io:8020 To know the names of nn1 and nn2 for dfs.namenode.rpc-address.cluster.nn1 & dfs.namenode.rpc-address.cluster.nn2 create a Sqoop job, type hostname and run.
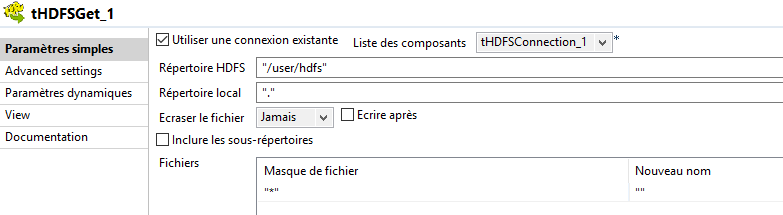
- Double click on "tHDFSGet" and set its properties:
- Check "Use an existing connection" and select the connection made by the component "tHDFSConnection"
- Add a HDFS folder: "/user/hdfs" (or another one)
- Add a local directory : "." (or another one)
- Add a Filemask.
In the example, the filemask is "*" because this job is looking up every file.
If you want to only search for files ending with the extension ".csv", you can enter "*.csv".
The star means "whatever" before ".csv".
- Run the job