Document datasets
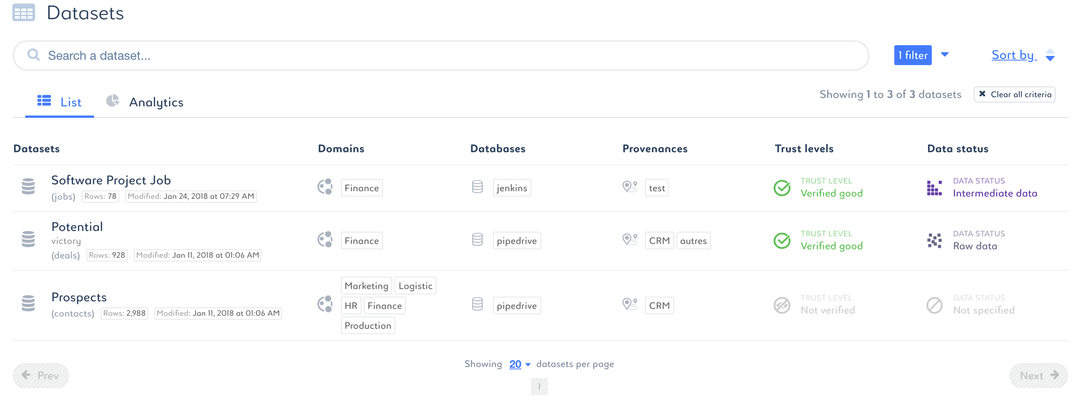
- Click the Datasets tab.
- Select the dataset you want to classify.
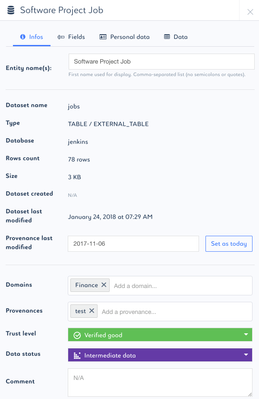
- Classify the dataset in this window.
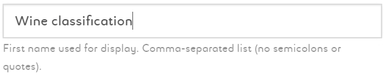
Edit name
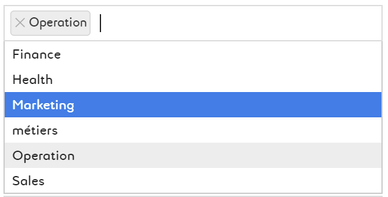
Tag domains the dataset belongs to
Tag the provenance of the dataset
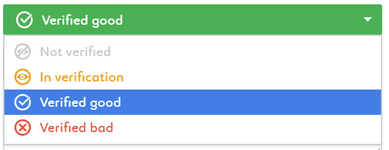
Tag the level of data trust
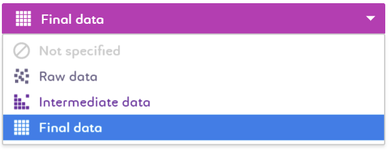
Tag the current status of the data
Add a comment to the dataset

Document personal data
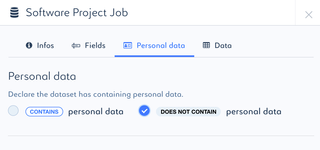
To access the personal data panel :
- Click the Datasets panel in the Data Governance portal
- Select a dataset
- Select the Personal data tab in the dataset overview
Tag dataset containing personal data
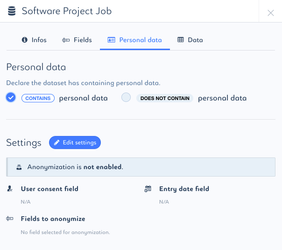
- Check "contains personal data" box if the dataset contains personal data
Document the consent and / or configure anonymization process
- Click to Edit Settings to document the consent and / or configure anonymization process
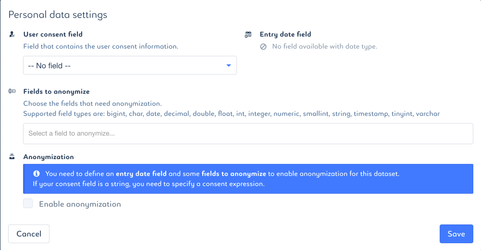
Tag the user consent field
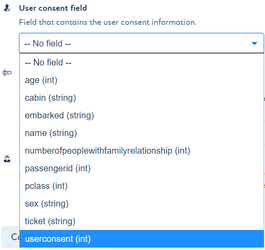
- Select the field specifying if the user consented to the use of his personal data
Default anonymization process does not use user consent field. It will be released at a later date.
Tag the entry date field
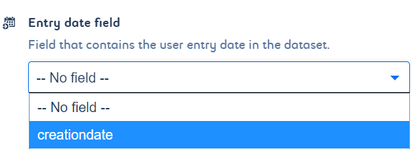

- Select the field specifying entry date
- Specify the number of days after entry date data will be anonymized
Entry date field is mandatory for anonymization process
Select fields to be anonymized

- Select fields to be anonymized
At least one field to be anonymized is mandatory for anonymization process
Enable anonymization

- Check "Enable anonymization" box to declare anonymization process
- Click on "Enable anonymization" button to save settings and anonymization job will launch depending on scheduling
Csv and parquet files on TABLE are supported in default anonymization process. More technical formats will be released at a later date (FILE and DIRECTORY are not currently supported).
Anonymization process substitute the existing data by a generated value respecting the same format.
This operation is not reversible.
Anonymization job
An default anonymization process in scala is proposed by Saagie. The code source is available here : https://github.com/saagie/outis.
You can use it as is, change it or replace it with one of your process.
To use it, build jar and create Spark processing job on platform with command line :
spark-submit \
--conf "spark.executor.extraJavaOptions='-Dlog4j.configuration=log4j.xml'" \
--conf spark.ui.showConsoleProgress=false \
--driver-java-options "-Dlog4j.configuration=log4j.xml" \
{file} -u user -t metastore_url datasetsToAnonymized_url callback_url
where :
user= user to launch jobmetastore_url= url of the hive metastore (exp : thrift://nn1:9083)datasetsToAnonymized_url= url to obtain datasets to anonymized (exp : http://IP_DATAGOVERNANCE:PORT/api/v1/privacy/datasets)callback_url= url to inform dataset is anonymized (exp : http://IP_DATAGOVERNANCE:PORT/api/v1/privacy/events/datasetAnonymized)
You can dowload the last version of the jar here :
Exceptions handling
No dataset anonymization if :
- You don't provide an entry date
- You don't provide a list of fields to anonymize
- If you provide a string field as an entry date without a pattern to parse the data
- Dataset isn't csv or parquet files on table
No record anonymization if :
- The value of the field to anonymize has a NULL value
- You try to replace a string field mark as a date without providing a pattern
- An error occured
Managed types
String anonymization :
The strings fields are anonymized by substitution (character by character)
- If the character is a digit, he is substituted by an another digit
- If the character is a letter, he is substituted by an another letter
- otherwise the character remains unchanged
Date anonymization :
If the field is a String type and tagged as a Date type, a randomized date in String format with the same pattern is generated
If the field is a Timestamp type, a randomized Timestamp is generated
if the field is a Date type, a randomized Date is generated
Numeric anonymization :
All numeric types are anonymized randomly. The generated value can not exceed the type max value.This covers these types : Byte, Short, Int, Long, Float, Double and BigDecimal.
Error
You can find execution errors of the job in Error Output part of Job Logs.